Experimental Results
Learning Curves
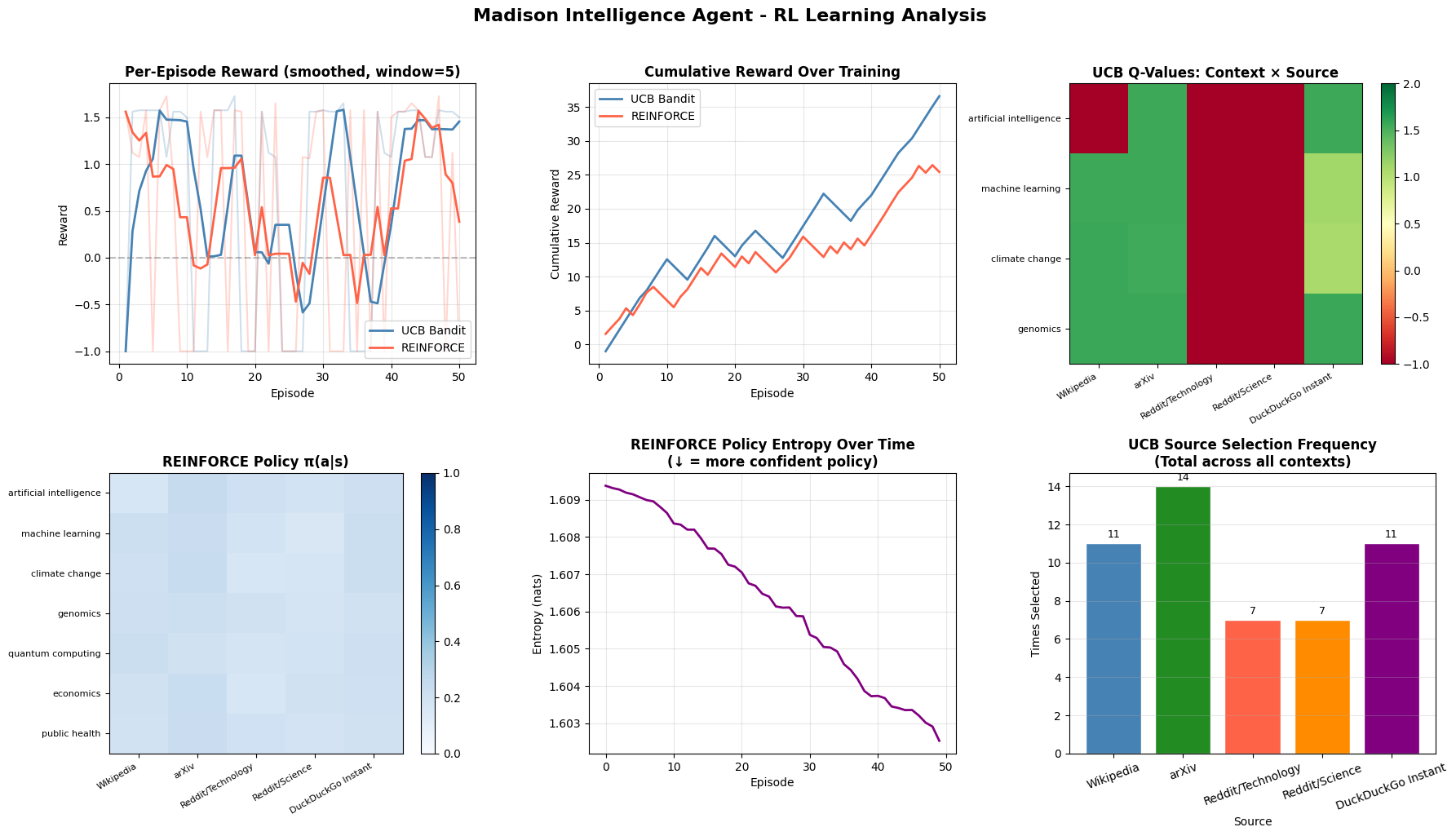
Per-episode reward, cumulative reward, Q-value heatmap, REINFORCE policy distribution, policy entropy over training, and source selection frequency.
Reinforcement learning for adaptive source selection. UCB Contextual Bandits and REINFORCE Policy Gradient on real live APIs.
Technical Report
System architecture, mathematical formulation, experimental results, analysis, ethical considerations, and references.
Source Code
Full implementation including UCB Bandit, REINFORCE, training loop, reward function, real API fetchers, statistical analysis, and visualizations.
Experimental Results
Per-episode reward, cumulative reward, Q-value heatmap, REINFORCE policy distribution, policy entropy over training, and source selection frequency.
Custom Tool
A standalone, reusable multi-component reward scoring tool built specifically for Madison's source selection problem. Evaluates three independent quality dimensions — not just binary success/failure.
| Component | Condition | Value |
|---|---|---|
r_success | Fetch succeeded | +1.0 |
r_success | Fetch failed | −1.0 |
r_length | Word count > 50 | +0.5 |
r_length | Word count < 10 | −0.2 |
r_relevance | Keyword overlap ratio | 0 – 0.3 |
Performance Summary
Comparison across all three agents. Welch t-test: t=0.987, p=0.329 (not statistically significant at alpha=0.05 — consistent with high API variance over 50 episodes).
| Metric | Random Baseline | UCB Bandit | REINFORCE | Winner |
|---|---|---|---|---|
| Avg Reward (Random baseline) | 0.778 | -- | -- | Baseline |
| Avg Reward (Late training) | 0.778 | 0.873 | 0.553 | UCB |
| Improvement over random | -- | +0.096 | −0.225 | UCB |
Demonstration
10-minute walkthrough covering notebook structure, live training, learning curves analysis, and before/after performance comparison.